排序算法
在本章中,我们将致力于研究针对对象集进行排序的算法。我们要对一个集合的元素进行重新排列,以使它们按照从小到大的顺序进行排列(或以此顺序生成一个新的副本)。Python中对数据排序提供了内在支持,包括对列表list类的sort方法,还有以排好的顺序生成一个包含任意元素集合的内置的sorted函数。这些内置函数使用了一些高级算法,并进行了高度的优化。我们很少有需要从头开始实现排序的特殊情况,但了解这些算法的底层逻辑和预期效率仍是有必要的。下面我们将逐个介绍。
在讨论各种排序算法之前,我们有必要了解我们应该从哪些方面来评价一个排序算法。
运行效率:我们期望排序算法的时间复杂度尽量低,且总体操作数量较少(时间复杂度中的常数项变小)。对于大数据量的情况,运行效率显得尤为重要。
就地性:顾名思义,「原地排序」通过在原数组上直接操作实现排序,无须借助额外的辅助数组,从而节省内存。通常情况下,原地排序的数据搬运操作较少,运行速度也更快。
稳定性:「稳定排序」在完成排序后,相等元素在数组中的相对顺序不发生改变。
稳定排序是多级排序场景的必要条件。假设我们有一个存储学生信息的表格,第 1 列和第 2 列分别是姓名和年龄。在这种情况下,「非稳定排序」可能导致输入数据的有序性丧失:
1 |
|
自适应性:「自适应排序」的时间复杂度会受输入数据的影响,即最佳时间复杂度、最差时间复杂度、平均时间复杂度并不完全相等。
自适应性需要根据具体情况来评估。如果最差时间复杂度差于平均时间复杂度,说明排序算法在某些数据下性能可能劣化,因此被视为负面属性;而如果最佳时间复杂度优于平均时间复杂度,则被视为正面属性。
是否基于比较:「基于比较的排序」依赖比较运算符(\(<、=、>\))来判断元素的相对顺序,从而排序整个数组,理论最优时间复杂度为\(O(n\log n)\) 。而「非比较排序」不使用比较运算符,时间复杂度可达\(O(n)\) ,但其通用性相对较差。
选择排序
选择排序是一种简单直观的排序手段,它的工作原理是:开启一个循环,每轮从未排序区间选择最小的元素,将其放到已排序区间的末尾。通过不断的交换操作,将第i小的元素放到数组编号为i的位置。代码如下:
1 | # 我们用k来记录未排序区间内的最小元素 |
算法性质:
时间复杂度为\(O(n^2)\),空间复杂度为\(O(1)\),非自适应性排序,原地排序,非稳定排序。
冒泡排序
冒泡排序是一种简单的排序方式,通过将相邻两个元素不断比较并交换完成整个序列的排序。由于在算法执行的过程中,较大的元素像是气泡般慢慢浮到数列的顶端,故叫冒泡排序。代码如下:
1 | def bubble_sort(nums: list[int]): |
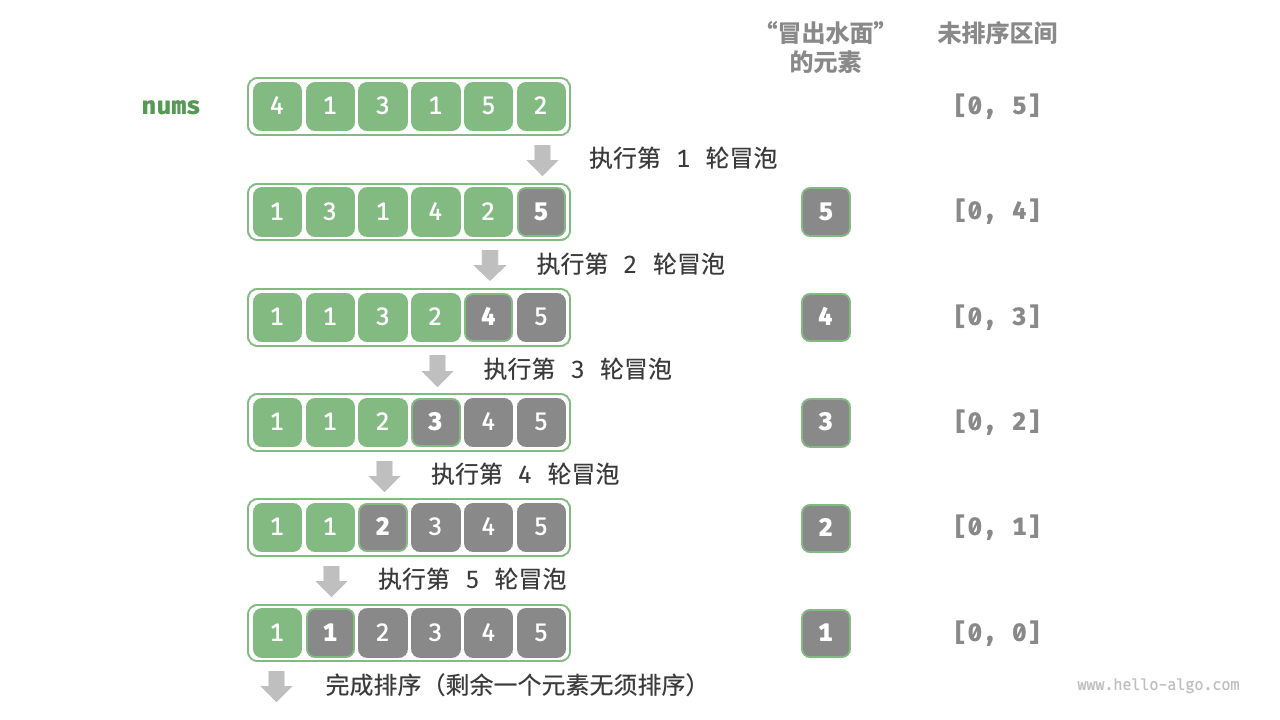
优化:我们发现,如果某轮冒泡中没有执行任何交换操作,说明数组已经完成排序,可以直接返回结果。因此,可以增加一个标志位flag来监测这种情况,一旦出现就立即返回。
1 | def bubble_sort_with_flag(nums: list[int]): |
算法性质:
时间复杂度为\(O(n^2)\),自适应排序,在引入flag优化后,对已经排序的数组时间复杂度可达到\(O(n)\)。空间复杂度为\(O(1)\)、原地排序、稳定排序。
插入排序
插入排序同样是一种简单直观的排序算法。它的工作原理为将待排列元素划分为已排序和未排序两部分,每次从未排序的元素中选择一个插入到已排序的元素中的正确位置。生活中,我们通常在打扑克时使用插入排序,即从牌桌上抓一张牌,按牌面大小插到手牌后,再抓下一张牌。
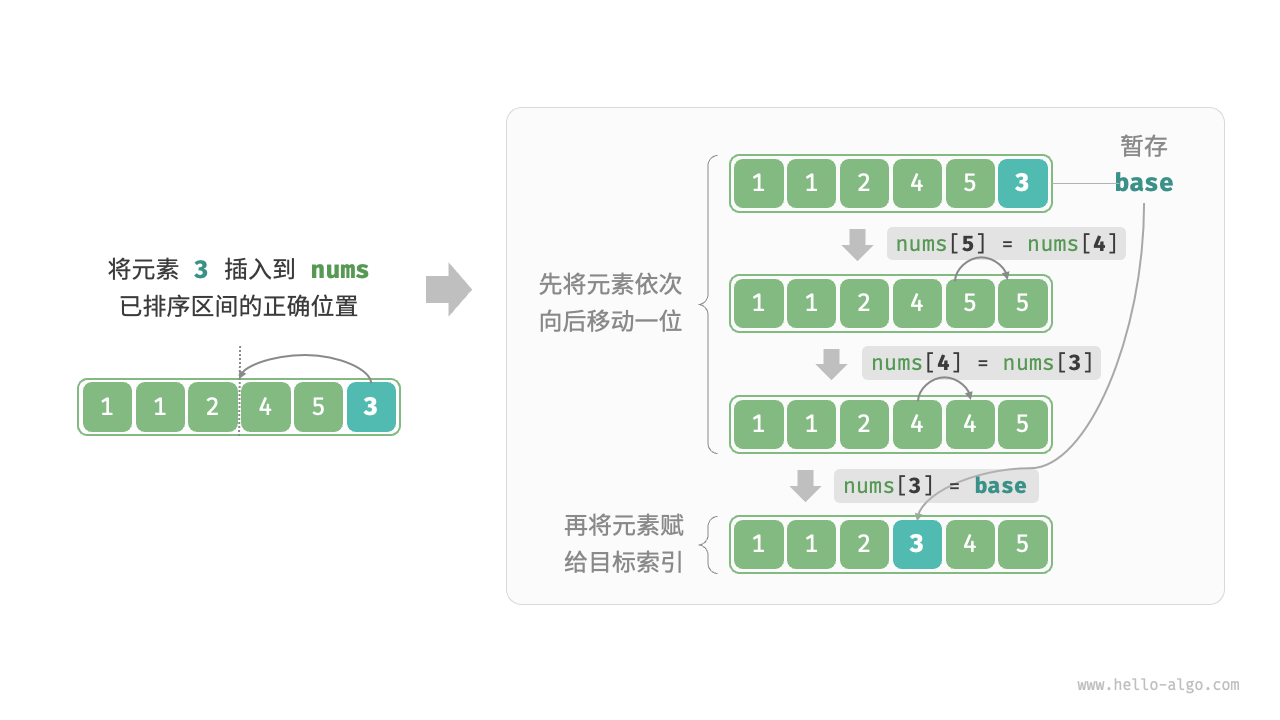
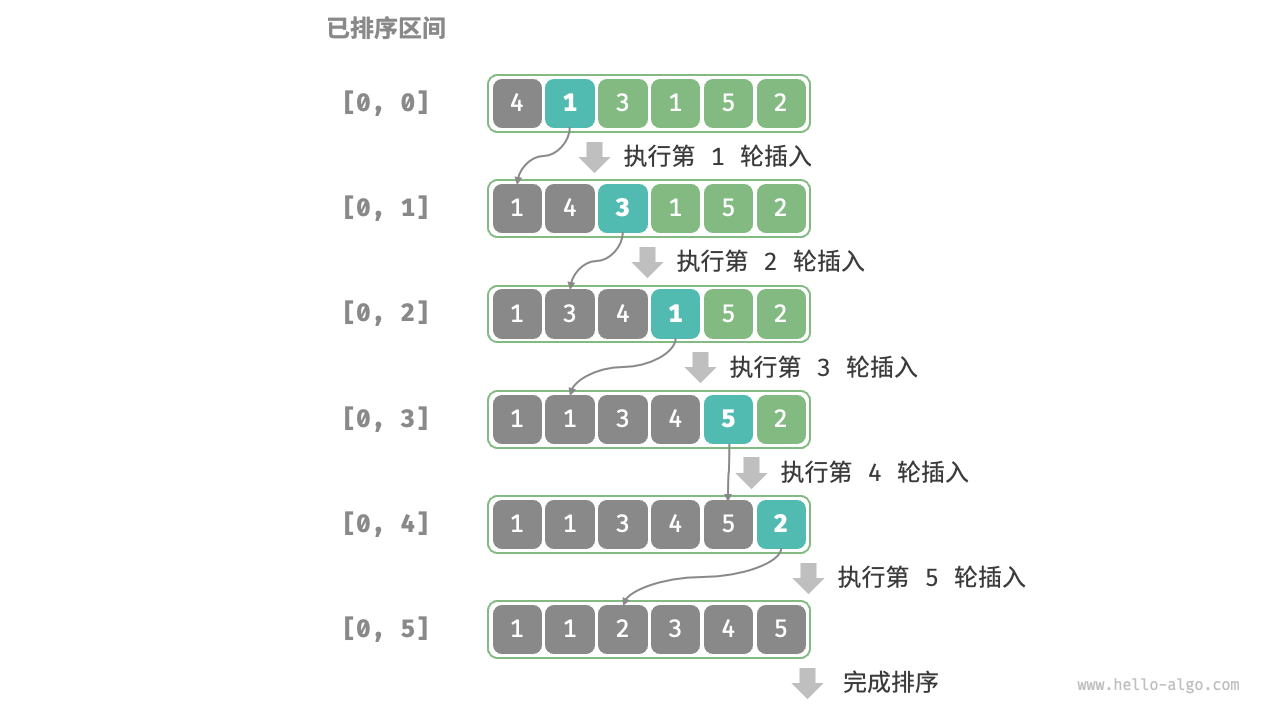
代码如下:
1 | def insertion_sort(nums: list[int]): |
算法性质:
时间复杂度\(O(n^2)\)、自适应排序、空间复杂度\(O(1)\)、原地排序、稳定排序
快速排序
快速排序是一种基于分治策略的排序算法,运行高效,应用广泛。