树
作为一种非线性的数据结构,树(tree)表现出与链表、数组等线性结构在组织关系上的差异,这种组织关系比一个序列中两个元素之间简单的“前”和“后”关系更加丰富和复杂。这种关系在树中是分层的(hierarchical),一些元素位于“上层”,而一些元素位于“下层”。树为数据提供了一个更加真实、自然的组织结构,由此实现的一系列算法也比使用线性数据结构要快得多。出于篇幅原因,我们仅在下文中介绍树的一些基本的内容。
树的定义和属性
正式的树的定义
通常我们将树T定义为存储一系列元素的有限节点集合,这些节点具有parent-children关系并且满足如下属性:
- 如果树T不为空,那它一定具有一个称为根节点的特殊节点,并且该节点没有父节点。
- 如果每个非根节点v都具有唯一的父节点w,每个具有父节点w的节点都是节点w的一个孩子。
注意,根据以上定义,一棵树可能为空,这意味着它不含有任何节点。这个约定也允许我们递归地定义一棵树,以使这棵树T要么为空,要么包含一个节点r(其称为树T的根节点),其他一系列子树的根节点是r的孩子节点。
其他节点关系
同一个父节点的孩子节点之间是兄弟关系。一个没有孩子的节点v称为外部节点。有一个或多个孩子的节点v称为内部节点。外部节点也称为叶子节点。
树的边和路径
树T的边指的是一对节点(u,v),u是v的父节点或v是u的父节点。树T当中的路径指的是一系列的节点,这些节点中任意两个连续的节点之间都是一条边。
有序树
如果树中每个节点的孩子节点都有特定的顺序,则称该树为有序树。我们将一个节点的子节点依次编号为第一个,第二个,第三个等。通常我们按照从左到右的顺序对兄弟节点进行排序。
树的抽象数据类型
我们用位置作为节点的抽象结构来定义树的抽象数据类型结构。一个元素存储在一个位置,并且位置信息满足树中的父节点和子节点的关系。一棵树的位置对象支持如下方法:
- p.element():返回存储在位置p中的元素。
树的抽象数据类型支持如下访问方法。允许使用者访问一棵树的不同位置:
- T.root():返回树T的根节点的位置。如果树为空,则返回None。
- T.is_root(p):如果位置p是树T的根,则返回True。
- T.parent(p):返回位置为p的父节点的位置。如果p的位置为树的根节点,则返回None。
- T.num_children(p):返回位置为p的孩子节点的编号。
- T.children(p):产生位置为p的孩子节点的一个迭代。
- T.is_leaf(p):如果位置节点p没有任何孩子,则返回True。
- len(T):返回树T所包含的元素的数量。
- T.is_empty():如果树T不包含任何位置,则返回True。
- T.positions():迭代地生成树T的所有位置。
- iter(T):迭代地生成存储在树T中的所有元素。
以上所有方法都接受一个位置作为参数,但是如果树T中的这个位置是无效的,则调用它就会触发一个VaiueError。我们将在之后的内容通过一棵树的所有位置来讨论迭代生成方法。
计算深度和高度
假定p是树T中的一个节点,那么p的深度就是节点p的祖先的个数,不包括p本身。这种定义表明树的根节点的深度为0.p的深度同样也可以按如下递归定义:
- 如果p是根节点,那么p的深度为0.
- 否则,p的深度就是其父节点的深度加1。
就这个定义,我们在下面给出计算树T中一个节点p的深度的简单递归算法。该算法递归地调用自身。
树类中计算深度的算法
1 | def depth(self,p): |
树T中节点p的高度的定义如下:
- 如果p是一个叶子节点,那么它的高度为0。
- 否则,p的高度是它孩子节点中的最大高度加1。
一颗非空树T的高度是树根节点的高度。除此之外,一颗非空树T的高度也等于其所有叶子节点深度的最大值。
计算高度的方法_height1
1 | def _height1(self): |
不幸的是,这个算法并不搞笑,在最坏的情况下,它的执行时间为\(O(n)\)。
不依赖先前的递归定义,我们可以更加高效地计算树的高度,使其执行时间为\(O(n)\)。为了这样做,我们将给予一棵树中的某个位置参数化一个函数,并计算以这个节点作为根节点的子树的高度。下面的代码段给出了示例。
计算一个以p节点为根节点的子树的高度
1 | def _height2(self,p): |
计算整个树或者一个给定位置作为根节点的子树的高度的Tree.height方法
1 | def height(slef,p=None): |
二叉树
二叉树是具有以下属性的有序树:
- 每个节点最多有两个子节点。
- 每个子节点被命名为左子节点或右子节点。
- 对于每个节点的子节点,在顺序上,左先于右。
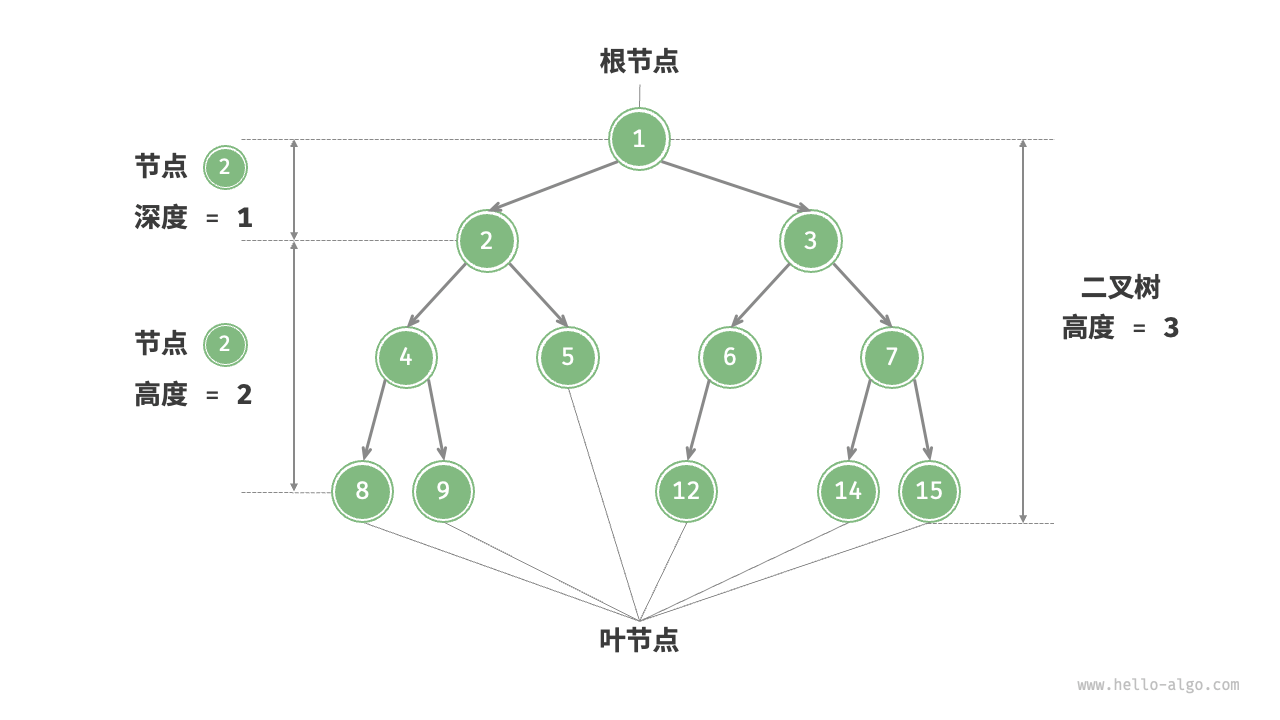
一些术语
- 「根节点 root node」:位于二叉树顶层的节点,没有父节点。
- 「叶节点 leaf node」:没有子节点的节点,其两个指针均指向 None 。
- 「边 edge」:连接两个节点的线段,即节点引用(指针)。
- 节点所在的「层 level」:从顶至底递增,根节点所在层为 1 。
- 节点的「度 degree」:节点的子节点的数量。在二叉树中,度的取值范围是 0、1、2 。
- 二叉树的「高度 height」:从根节点到最远叶节点所经过的边的数量。
- 节点的「深度 depth」:从根节点到该节点所经过的边的数量。
- 节点的「高度 height」:从距离该节点最远的叶节点到该节点所经过的边的数量。
二叉树的类型
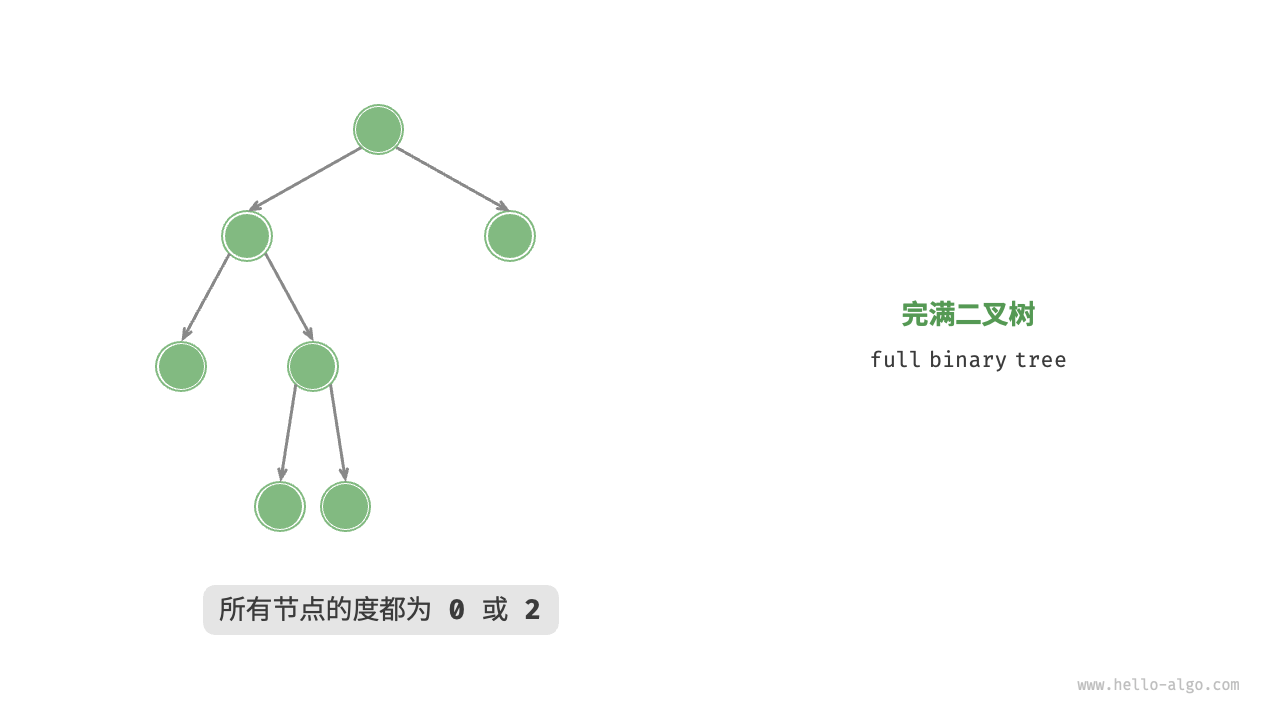
满二叉树(full binary tree)是一种二叉树,其中每个节点都具有0或2个子节点。定义满二叉树的另一种方法是递归定义。满二叉树是:
- 单个顶点(单个节点作为根节点)
- 根节点有两个子树,并且两个子树都是满二叉树的树
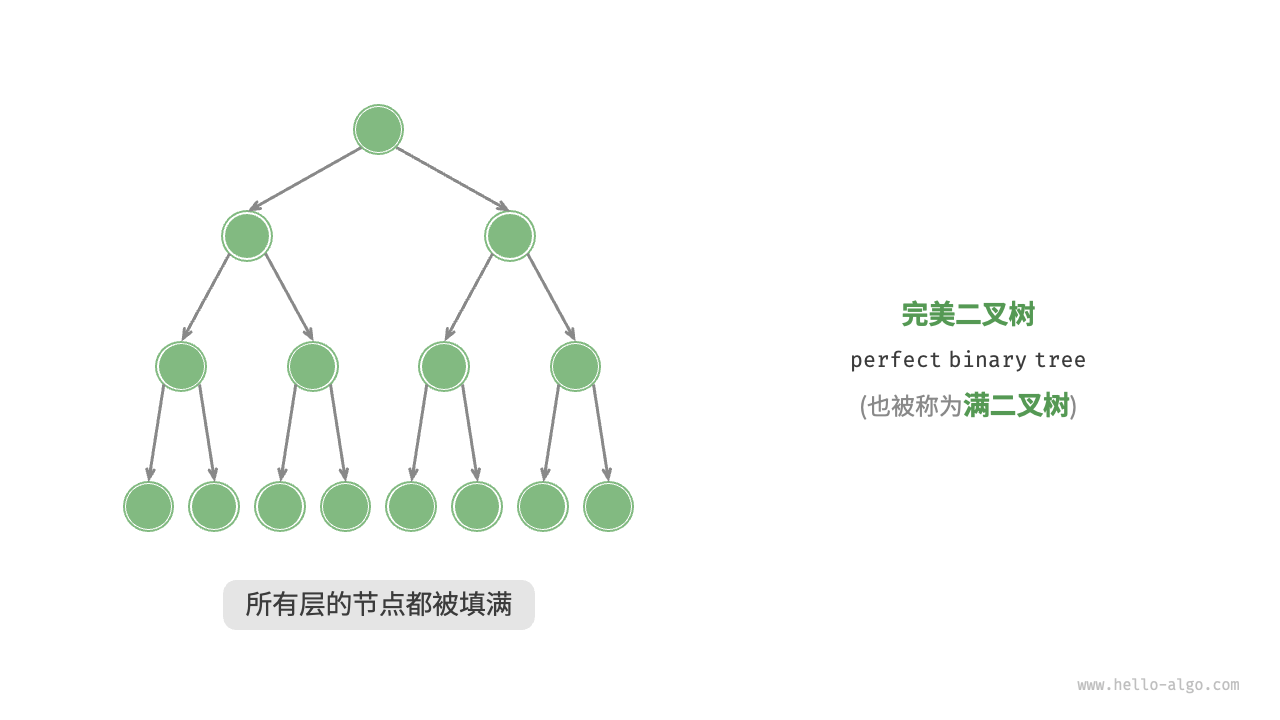
完美二叉树(perfect binary tree)是一种二叉树,其中所有的内部节点都有两个子节点,并且所有的叶节点都具有相同的深度或相同的层级。完美二叉树是满二叉树。
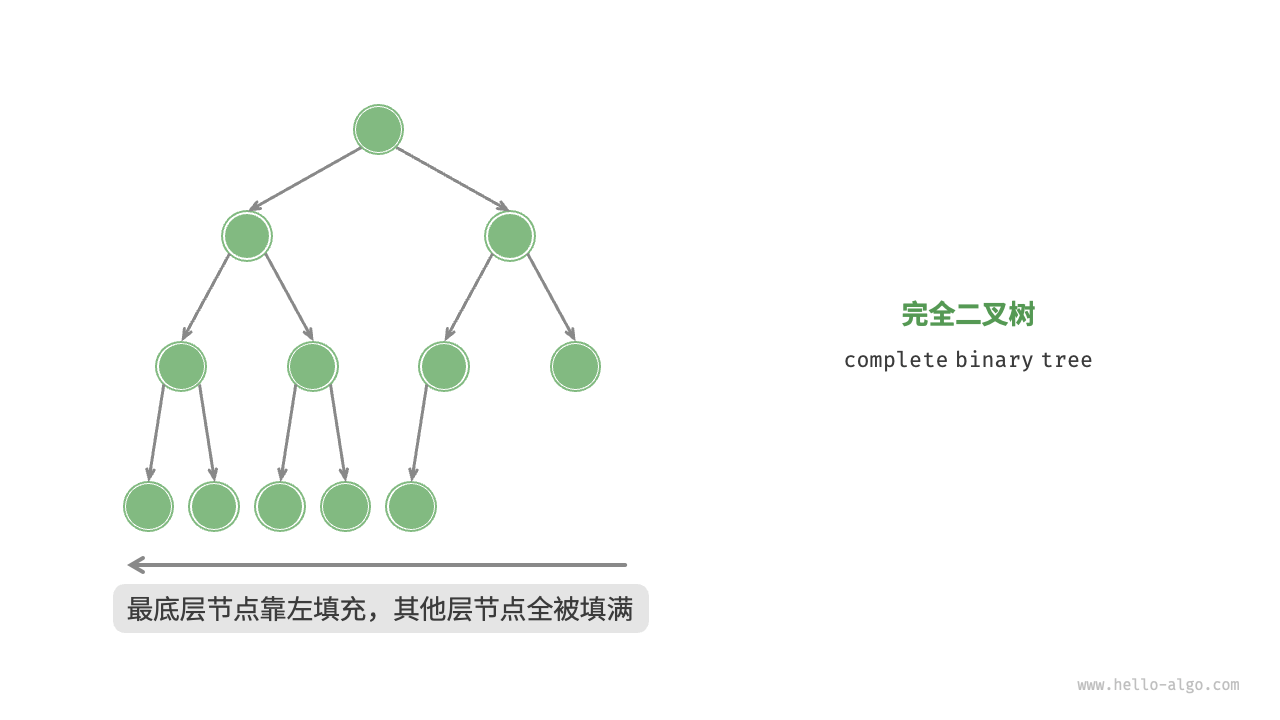
完全二叉树(complete binary tree)是这样的二叉树:除了最后一层外,每一层都被完全填满,并且最后一层的所有节点都尽可能远离左边。因此,完美的树总是完全的,但完全的树并不总是完美的。使用数组可以有效地表示完全二叉树。
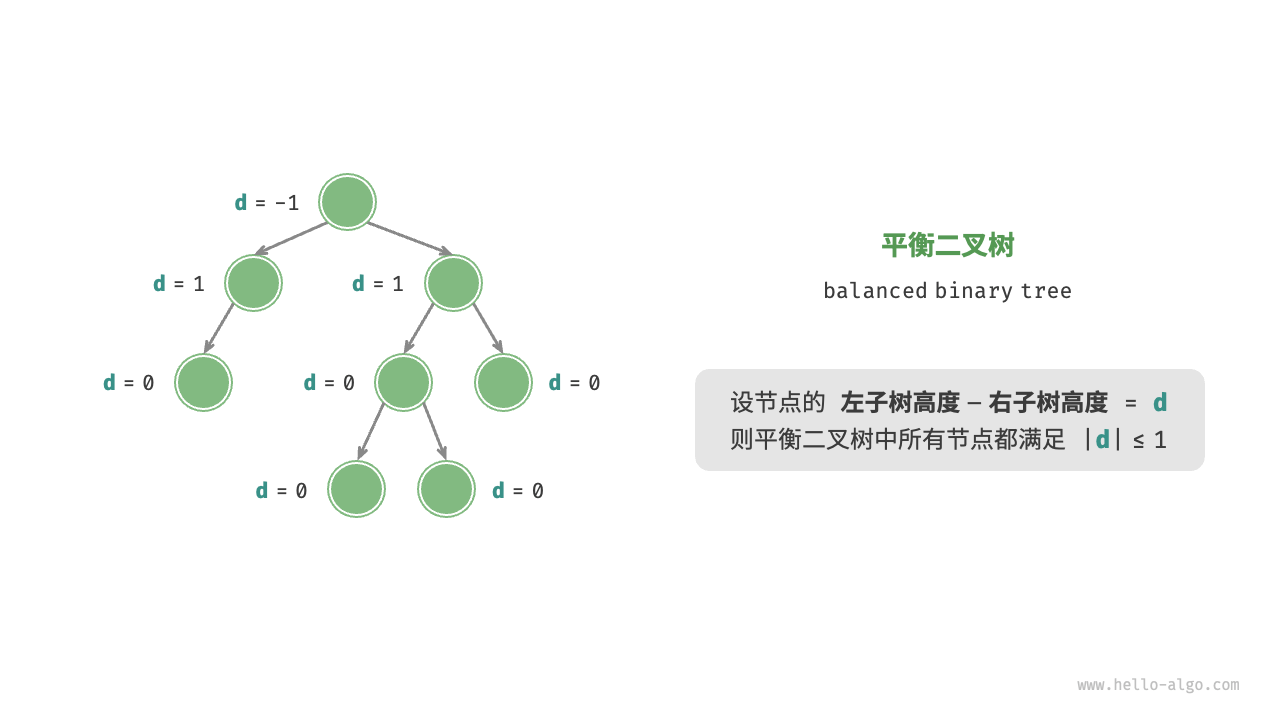
平衡二叉树(balanced binary tree)是一种二叉树结构,其中每个节点的左子树和右子树的高度相差不超过1(或倾斜不大于1)。你也可以考虑它是这样的树,其中没有叶子比其他任何叶子距离根更远(对“更远”有不同的定义)。
退化(病态)二叉树(degenerate or pathological tree)是指每个父节点只有一个关联的子节点,这意味着它本质上退化成了链表,丧失了几乎全部使用二叉树的优势。而另一种极端情况则是完美二叉树,它可以充分发挥出二叉树“分治”的优势。
二叉树的属性
二叉树节点与高度之间存在如下关系:
设\(T\)为非空二叉树,\(n、n_E、n_I\)和\(h\)分别表示\(T\)的节点数、外部节点数、内部节点数和高度,则\(T\)具有如下属性:
- \(h+1\le n\le 2^{h+1}-1\)
- \(1\le n_E\le 2^h\)
- \(h\le n_I\le 2^h-1\)
- \(\log(n+1)-1\le h\le \frac{(n-1)}{2}\)
另外,若\(T\)是完全二叉树,则\(T\)具有如下性质:
- \(2h+1\le 2^{h+1}-1\)
- \(h+1\le n_E\le 2^h\)
- \(h\le n_I\le 2^h-1\)
- \(\log(n+1)-1\le h\le \frac{(n-1)}{2}\)
完全二叉树中另有如下命题:
在非空完全二叉树\(T\)中,有\(n_E\)个外部节点和\(n_I\)个内部节点,则\(n_E=n_I+1\)
树的实现
二叉树的链式存储结构
实现一个二叉树T的一个自然方法便是使用链式存储结构。一个节点包含多个引用:指向存储在位置p的元素的引用,指向p的孩子节点和双亲节点的引用。若p是T的根节点,则p的parent字段为None。同样,若p没有左子节点或右子节点,则相关字段即为None。树本身包含一个实例变量,存储指向根节点的引用,还包含一个size变量,表示T的所有节点数。在以下代码段中,我们给出一个二叉树的简单的实现。
二叉树的初始化
1 | class TreeNode: |
在二叉树中插入和删除节点
1 | # 插入与删除节点 |
需要注意的是,插入节点可能会改变二叉树的原有逻辑结构,而删除节点通常意味着删除该节点及其所有子树。因此,在二叉树中,插入与删除通常是由一套操作配合完成的,以实现有实际意义的操作。
二叉树的遍历
从物理结构的角度来看,树是一种基于链表的数据结构,因此其遍历方式是通过指针逐个访问节点。然而,树是一种非线性数据结构,这使得遍历树比遍历链表更加复杂,需要借助搜索算法来实现。
二叉树常见的遍历方式包括层序遍历、前序遍历、中序遍历、后序遍历等。
层序遍历
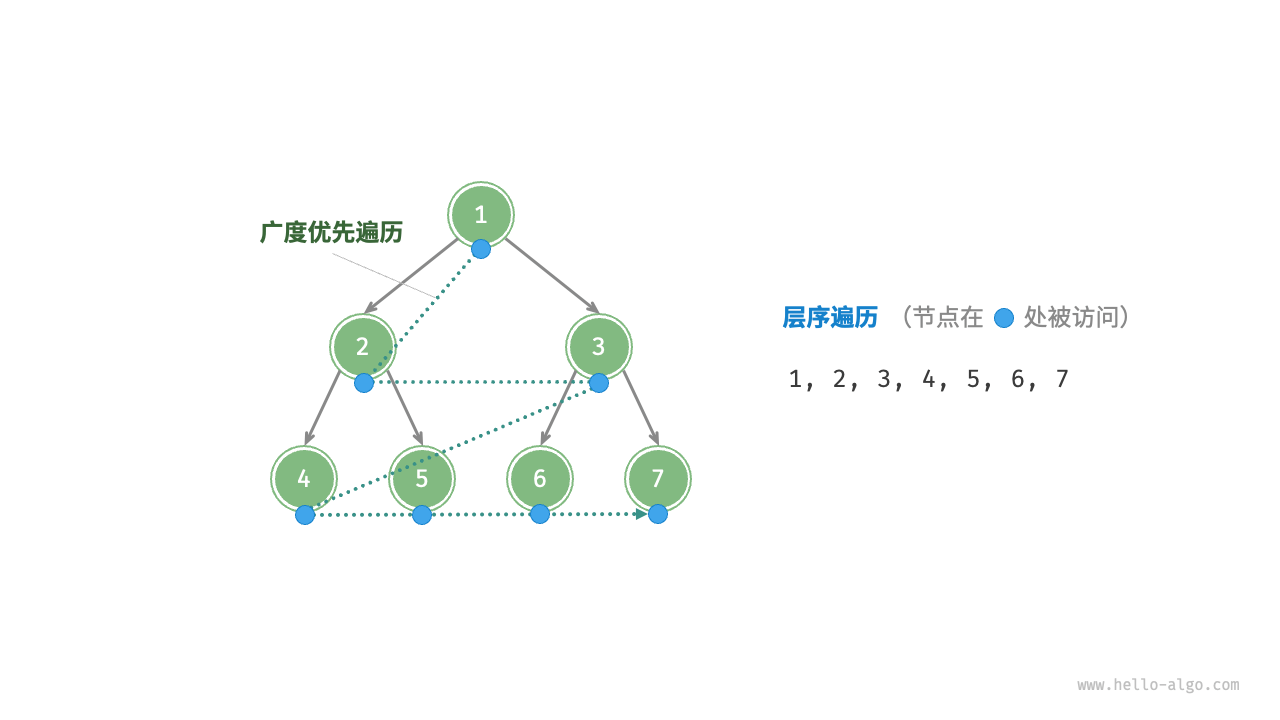
如下图所示,层序遍历(level-order traversal)从顶部到底部逐层遍历二叉树,并在每一层按照从左到右的顺序访问节点。层序遍历本质上属于广度优先遍历(breadth-firth traversal),也成广度优先搜索(breadth-first search,BFS),它体现了一种“一圈一圈向外扩展”的逐层遍历方式。
通常,我们使用一个队列来产生FIFO访问节点的顺序语义。整体的运行时间为\(O(n)\)
代码实现二叉树的层序遍历
1 | def level_order(root: TreeNode | None) -> list[int]: |
我们用一个例题来加深对BFS的理解:
LeetCode 127.单词接龙 Hard
字典 wordList 中从单词 beginWord 和 endWord 的 转换序列 是一个按下述规格形成的序列 beginWord -> s1 -> s2 -> ... -> sk:
- 每一对相邻的单词只差一个字母。
- 对于 1 <= i <= k 时,每个 si 都在 wordList 中。注意, beginWord 不需要在 wordList 中。
- sk == endWord
给你两个单词 beginWord 和 endWord 和一个字典 wordList ,返回 从 beginWord 到 endWord 的 最短转换序列 中的 单词数目 。如果不存在这样的转换序列,返回 0 。
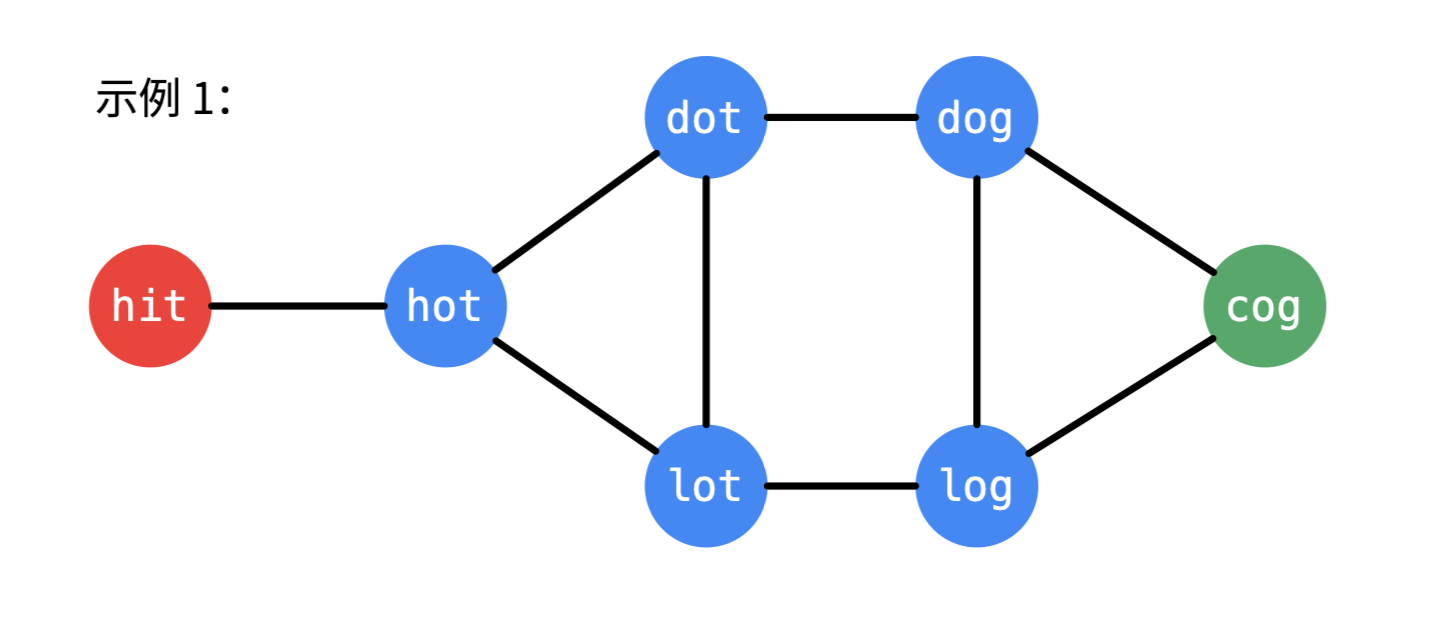
示例 1:
输入:beginWord = "hit", endWord = "cog", wordList = ["hot","dot","dog","lot","log","cog"]
输出:5
解释:一个最短转换序列是 "hit" -> "hot" -> "dot" -> "dog" -> "cog", 返回它的长度 5。
示例 2:
输入:beginWord = "hit", endWord = "cog", wordList = ["hot","dot","dog","lot","log"]
输出:0
解释:endWord "cog" 不在字典中,所以无法进行转换。
提示:
- 1 <= beginWord.length <= 10
- endWord.length == beginWord.length
- 1 <= wordList.length <= 5000
- wordList[i].length == beginWord.length
- beginWord、endWord 和 wordList[i] 由小写英文字母组成
- beginWord != endWord
- wordList 中的所有字符串 互不相同
思路:
一种较为简单的思路是:我们考虑这样一个双向队列,队列中的元素是一个单词currentword和由它到达endword需要的最短步长steps构成的元组。我们可以执行简单的BFS算法,如下图所示:
我们从hit出发,此时hit所属的步长为1,接着我们搜索到了hot,此时hot所属步长为2,然后我们搜索到了dot和lot,为了避免出现重复循环地搜索,我们禁止搜索到已经出现过的单词,这种操作可以通过将搜索到的单词从字典中删除并转移到另一个列表中完成。通过不断地搜索,即可得到最后的答案。代码如下:
1 | from collections import deque |
不幸的是,这种代码在逻辑上是可行的,但在效率上存在一些问题,我们可以采用双向BFS来提高我们的效率。
思路二(双向BFS):
我们不难看出,我们最初的想法是从beginword开始,通过发散式地搜索来找出所有的可能性,当数据量过大时,所需要的检索时间会进行指数级的膨胀。因此,我们可以考虑从beginword和endword两端同时开始检索,选取两个集合中较少的一个作为搜索的起点直到它的数量超过另一个。这样做的好处是,我们更好地控制了数据不断增长的速度,使得面对大数据量时依然保持不错的性能。代码如下:
1 | class Solution: |
深度优先搜索(DFS):
相应地,前序、中序和后序遍历都属于「深度优先遍历depth-first traversal」,也称「深度优先搜索 depth-first search, DFS」,它体现了一种“先走到尽头,再回溯继续”的遍历方式。
下图展示了对二叉树进行深度优先遍历的工作原理。其中前序遍历强调,我们需要先访问T的根,然后递归地访问子树的根。如果这棵树是有顺序的,则根据孩子的顺序遍历子树。后序遍历强调先访问子树的叶子节点,然后逐级向上进行访问。中序遍历强调“从左到右”非正式地访问T的节点。事实上,对于每个位置p,p将在其左子树之后及右子树之前被中序遍历访问。
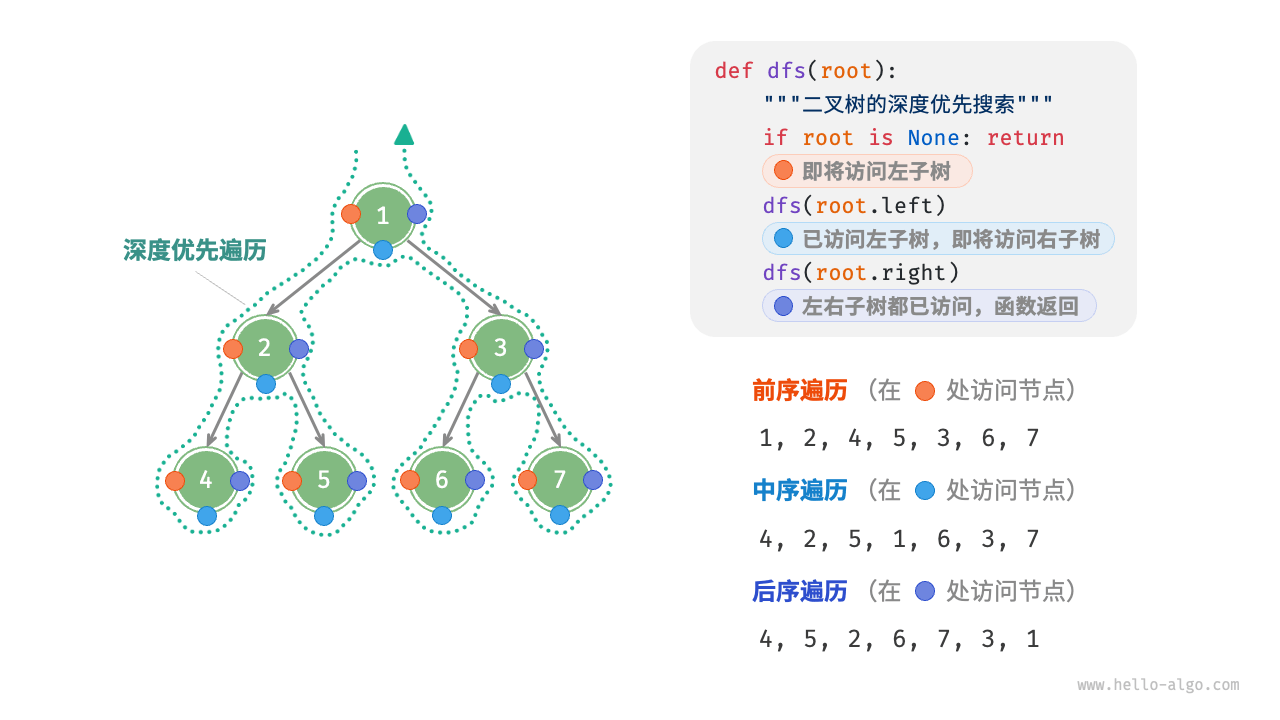
代码实现
1 | def pre_order(root: TreeNode | None): |