链表
在本章中,我们将介绍一种名为链表的数据结构,它为基于数组的序列提供了另一种选择。基于数组的序列和链表都能够对其中的元素保持一定的顺序,但采用的方式截然不同。数组提供更加集中的表示法,一个大的内存块能够为许多元素提供存储和引用。相对的,一个链表依赖于更多的分布式表示方法,采用称作节点的轻量级对象,分配给每一个元素。每个节点维护一个指向它的元素的引用,并含一个或多个指向相邻节点的引用,这样做的目的是为了集中地表示序列的线性顺序。
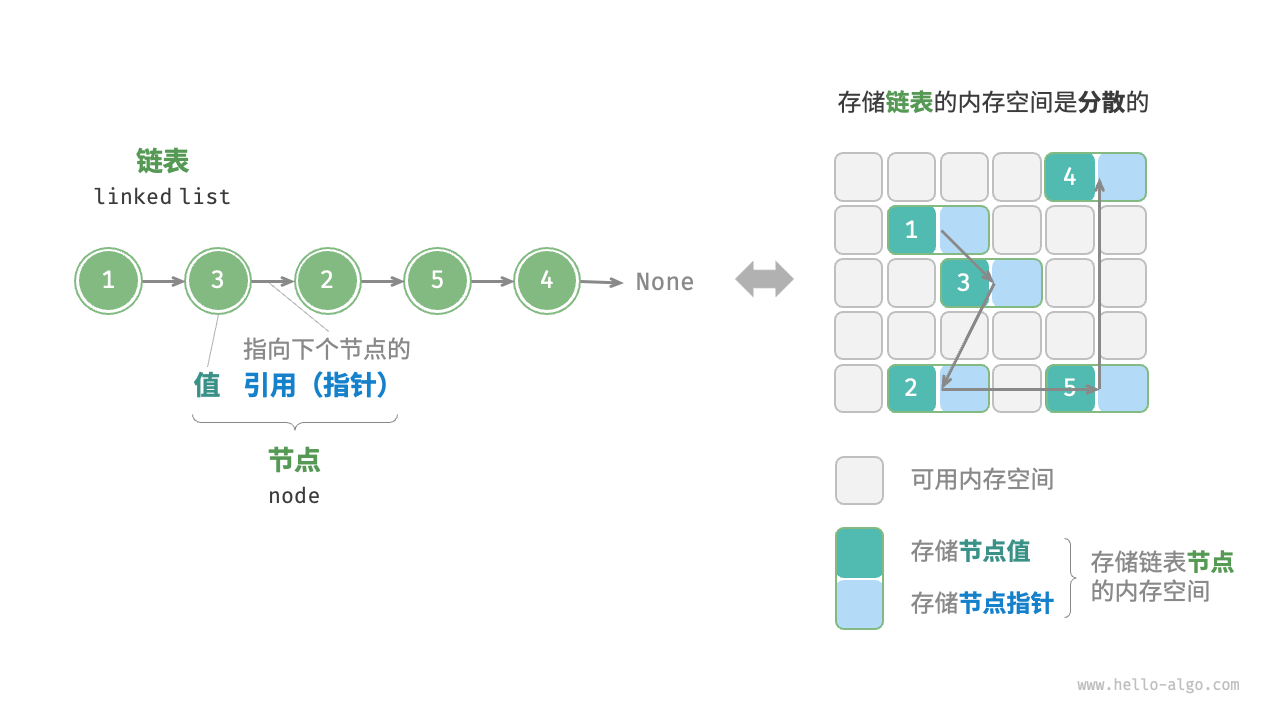
内存空间是所有程序的公共资源,在一个复杂的系统运行环境下,空闲的内存空间可能散落在内存各处。我们知道,存储数组的内存空间必须是连续的,而当数组非常大时,内存可能无法提供如此大的连续空间。此时链表的灵活性优势就体现出来了。链表的设计使得各个节点可以分散存储在内存各处,它们的内存地址无须连续。
链表的定义类
1 | class ListNode: |
1.单向链表
链表中最简单的一种是单向链表,它包含两个域,一个信息域和一个指针域。这个链接指向链表中的下一个节点,而最后一个节点则指向一个空值。因此在相同数据量下,链表比数组占用更多的内存空间。
一个简单的单向链表的流程图
初始化链表
建立链表分为两步,第一步是初始化各个节点对象,第二步是构建节点之间的引用关系。初始化完成后,我们就可以从链表的头节点触发,通过引用指向next一次访问所有节点
1 | # 初始化链表 1 -> 3 -> 2 -> 5 -> 4 |
我们通常将头节点当作链表的代称,比如以上代码中的链表可记作链表n0
插入节点
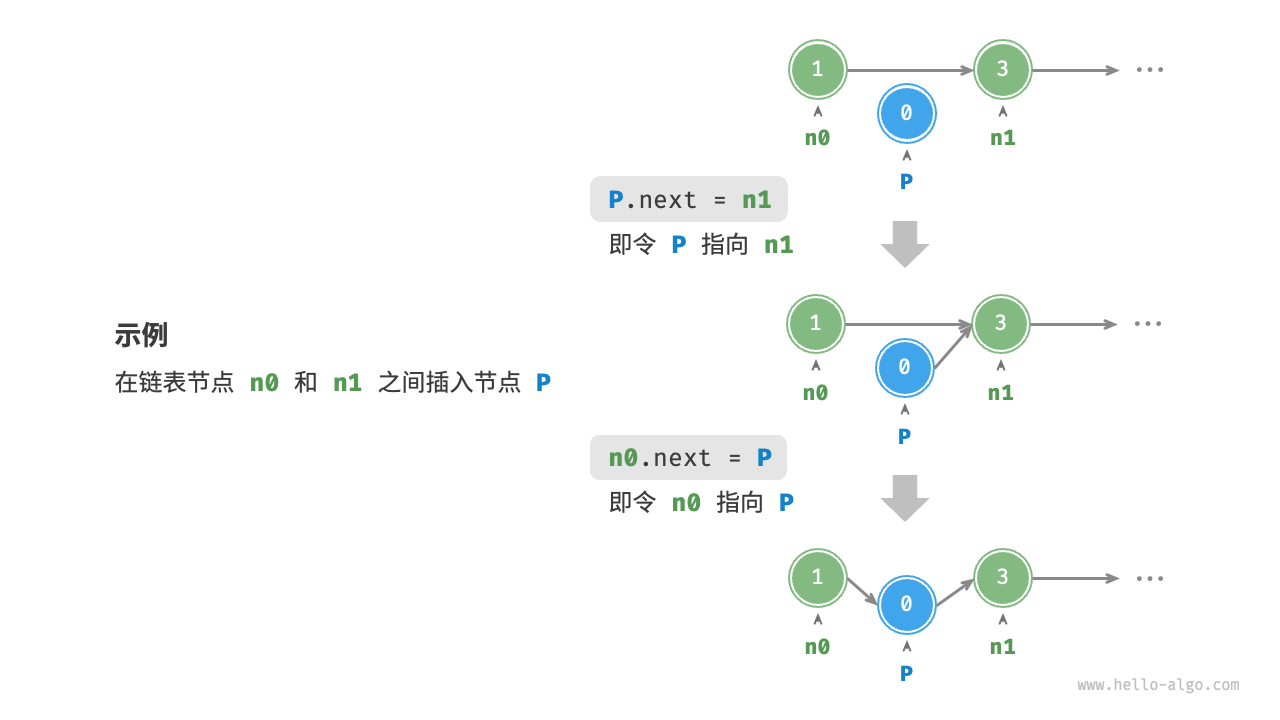
在链表中插入节点非常容易,如下图所示,假设我们想在相邻的两个节点n0和n1之间插入一个新节点p,则只需改变两个节点引用(指针)即可,时间复杂度为\(O(1)\)。相比之下,数组中插入元素的时间复杂度为\(O(n)\),在大数据量下的效率较低。
链表插入节点示例
1 | def insert(n0: ListNode, P: ListNode): |
删除节点
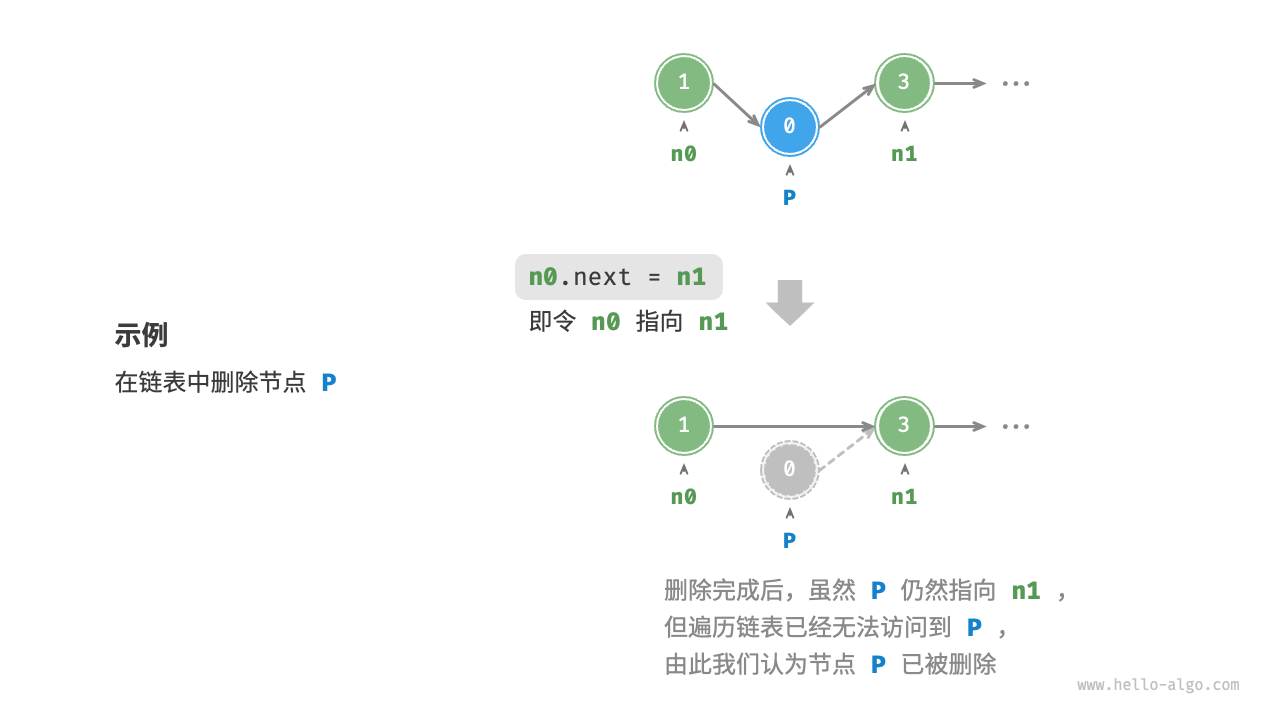
如下图所示,在链表中删除节点也变得非常方便,只需要改变一个节点的引用(指针)即可。
请注意,尽管在删除操作完成后节点 P 仍然指向 n1 ,但实际上遍历此链表已经无法访问到 P ,这意味着 P 已经不再属于该链表了。
1 | def remove(n0: ListNode): |
访问节点
在链表中访问节点的效率较低。对比数组来说,我们可以在\(O(1)\)时间内访问数组中的任意元素。链表则需要从头节点出发,逐个向后遍历,直至找到目标节点。也就是说,访问链表的第\(i\)个节点需要循环\(i-1\)轮,时间复杂度为\(O(n)\)。
1 | def access(head: ListNode, index: int) -> ListNode | None: |
查找节点
遍历列表,查找其中值为target的节点,输出该节点在链表中的索引。此过程也属于线性查找。代码如下所示。
1 | def find(head: ListNode, target: int) -> int: |
1.1 用单向链表实现栈
在这一部分,我们将通过给出一个完整栈ADT的Python实现来说明单向链表的使用。设计这样的实现,我们需要决定用链表的头部或尾部来实现栈顶。最好的选择显而易见:因为只有在头部,我们才能在一个常数时间内有效地插入和删除元素。由于所有栈操作都会影响栈顶,因此规定栈顶在链表的头部。
单向链表实现栈ADT
1 | class LinkedStack: |
1.2 用单向链表实现队列
正如用单向链表实现栈ADT一样,我们可以用单向链表实现队列ADT,且所有操作支持最坏情况的时间为\(O(1)\)。由于需要对队列的两端执行操作,我们显式地为每个队列维护一个_head和一个_tail指针作为实例变量。一个很自然的做法是,将队列的前段和链表的头部对应,队列的后端与链表的尾部对应,因为必须使元素从队列的尾部进入队列,从队列的头部出队列(我们很难高效地从单向链表的尾部删除元素)。链表队列(LinkQueue)类的实现如以下代码所示。
用单向链表实现队列ADT
1 | class LinkedQueue: |
用单向链表实现队列的很多方面和用LinkedStack类实现非常相似,如嵌套_Node类的定义。链表队列的LinkedQueue的视线类似于LinkedStack的出栈,即删除队列的头部节点,但也有一些细微的差别。因为队列必须准确的维护尾部的引用(栈的实现中没有维护这样的变量)。通常,在头部的操作对尾部不产生影响。但在一个队列中调用元素出队列操作时,我们要同时删除列表的尾部。同时为了确保一致性,还要设置self._tail为None。
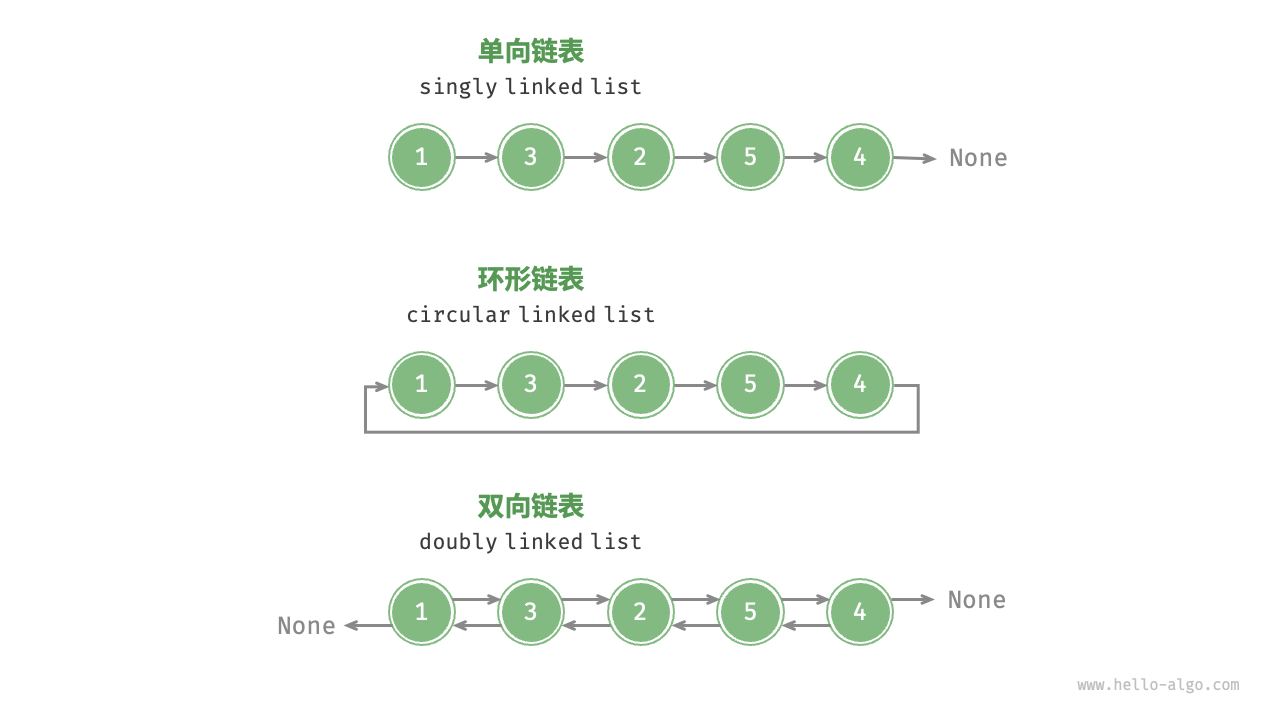
2.循环链表(环形链表)
在链表中,我们可以使单向链表尾部节点的“next”指针指向链表的头部,由此来获得一个更切实际的循环链表的概念。在循环链表中,任意节点都可以视作头节点。循环链表也可以实现一个循环队列类,这里不再赘述。
3.双向链表
在单向链表中,每个节点为其后继节点维护一个引用。我们已经说明了在管理一个序列的元素时如何使用这样的表示方法。然而,单向链表的不对称性产生了一些限制。我们强调过可以有效地想一个单向链表内部的任意位置插入一个节点,也可以在头部轻松删除一个节点,但是不能有效删除链表尾部的节点。更一般化的说法是,如果仅给定链表内部指向任意一个节点的引用,我们很难有效地删除该节点,因为我们无法立即确定待删除节点的前驱节点(而且删除处理中该前驱节点需要更新它的“next”引用)。
为了更好的对称性,我们定义了一个双向链表。与单向链表相比,双向链表记录了两个方向的引用。双向链表的节点定义同时包含指向后继节点(下一个节点)和前驱节点(上一个节点)的引用(指针)。相较于单向链表,双向链表更具灵活性,可以朝两个方向遍历链表,但相应地也需要占用更多的内存空间。这些列表支持更多各种时间复杂度为\(O(1)\)的更新操作,这些更新操作包括在列表的任意位置插入和删除节点。我们会继续用“next”表示指向当前节点的后继节点的引用,并引入“prev”引用其前驱节点。
头哨兵和尾哨兵
在操作接近一个双向链表的边界时,为了避免一些特殊情况,在链表的两端都追加节点是很有用处的:在列表的起始位置添加头节点(header),在列表的结尾位置添加尾节点(tailer)。这些“特定”的节点被称为哨兵。这些节点中并不存储主序列的元素。特别的,头节点有时会存储链表长度等基本信息。
当使用哨兵节点时,一个空链表需要初始化,使头节点的“next”域指向尾节点,并令尾节点的“prev”域指向头节点。哨兵节点的其他域是无关紧要的。对于一个非空的链表,头节点的“next”域将指向一个序列中第一个真正包含元素的节点,对应的尾节点的“prev”域指向这个序列中最后一个包含元素的节点。
使用哨兵的优点
虽然不使用哨兵节点就可以实现双向链表,但哨兵只占用很小的额外空间就能极大地简化操作的逻辑。最明显的是,头和尾节点从来不改变————只改变头节点和尾节点之间的节点。此外,可以用统一的方式处理所有插入节点操作,因为一个新节点总是被放在一对已知节点之间。类似地,每个待删除的元素都是确保被存储在前后都有邻居的节点中的。
双向链表的基本实现
1 | class ListNode: |
下图给出了常见的链表种类